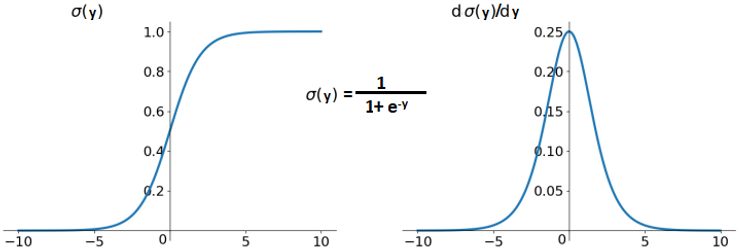# 8. 가중치 초기화
cost-function의 손실 함수 그래프가 아래와 같이 생겼다 할 때,
동일한 경사하강법을 사용하더라도 최저점이 다를 수 있습니다.
그래서 cost-function에 대해 경사 하강법을 수행했습니다.
그리고 오른쪽 봉우리에서 시작한다면 더욱 안 좋은 값이 나오게 됩니다.
대충 보았을 때, 좋은 학습을 위한 조건을 두가지 정도 볼 수 있습니다.
1. 어떻게 내려 갈 것인가?
2. **어디서 시작할 것인가?**
상황에 맞는 적절한 \*\*가중치 초기화(Weight initalization)\*\*방법을 사용하여 2번 항목을 정하게 됩니다.
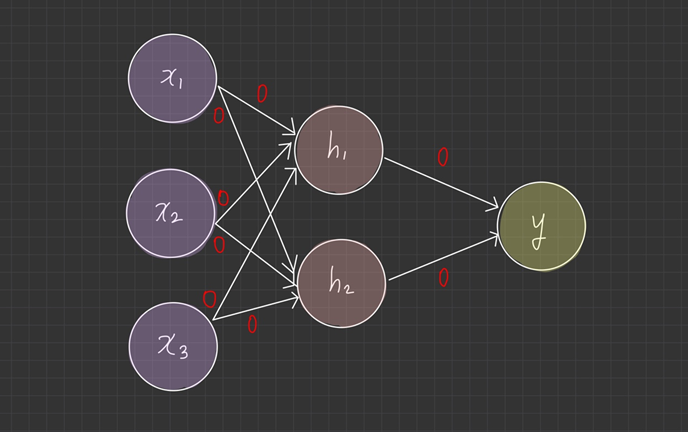
## 0으로 초기화 한다면?
가장 간단한 방법은 모든 파라미터를 0으로 시작하는 방식입니다.
가중치가 전부 0이면, 가중합이 0이 되므로, activation function은 0을 받아서
항상 같은 값을 출력하게 됩니다. 결과적으로 학습이 진행되지 않습니다.
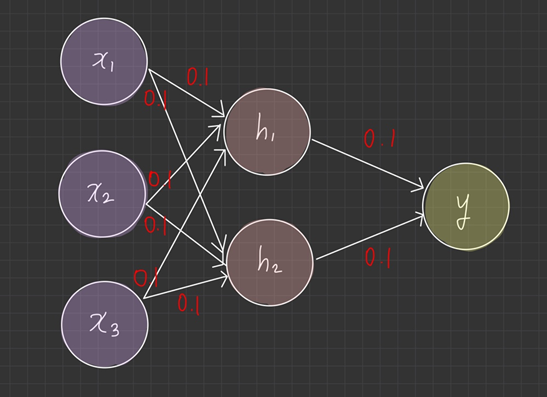
## 상수로 초기화 한다면?
실제 뉴런은 2개지만 1개와 똑같은 의미를 가지게 됩니다.
네트워크의 표현 능력이 제한되어 복잡한 패턴을 학습하는데 어려움을 겪을 수 있습니다.
## 랜덤하게(가우시안 분포) 초기화 한다면?
일단, Single neuron에서 예제를 봅시다.
$$
z = w\_1x\_1 + w\_2x\_2 + ... + w\_nx\_n
$$
입력 특성의 개수(n)가 점점 많아진다고 할 때, 가중치는 어떻게 변해야 할까요?
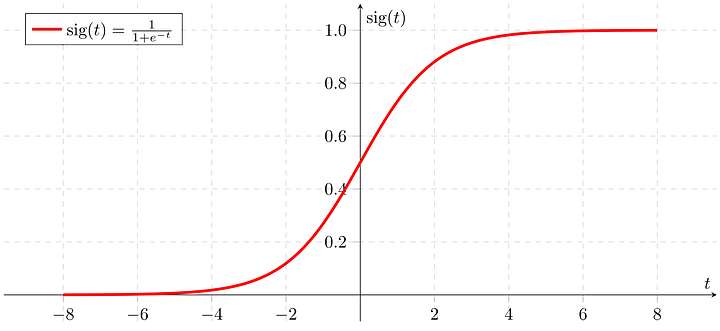
일단 계산후에, sigmoid를 사용한다고 하고, sigmoid를 보러 가봅시다.
sigmoid는 엄청 큰 값이나 작은 값을 가지면 0과 1에 수렴하는 특성이 있습니다.
고정적인 가중치를 가질 때, 입력 특성의 개수(n)이 많아지게 되면 엄청 큰 값을 가질 확률이
높아지고 이는 sigmoid의 출력이 1에 가까워지고, 기울기가 0에 가까워 집니다.
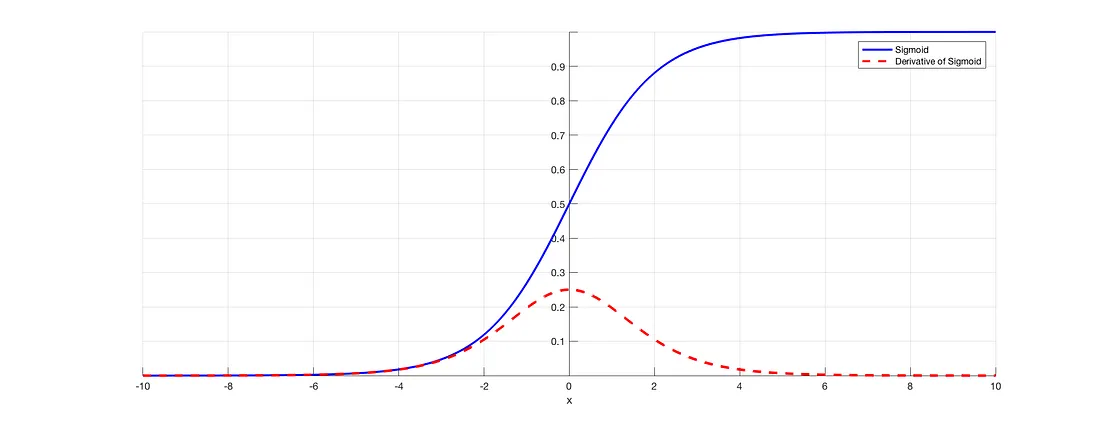
기울기 = 미분입니다. 저희는 역전파 과정에서 chain-rule에 의하여 계속 기울기를 곱하게 되는데,
sigmoid는 가장 기울기가 높은 지점이 0.25이며, 원점에서 멀어질 수록 0에 수렴합니다.
1보다 작은 값이 누적해서 곱해지면서 기울기가 0에 가까워 지면, 업데이트가 안 일어나는 문제
Gradient Vanishing이 발생하게 됩니다.
**그럼 우리는 입력 특성의 개수(n)이 많아지면, 가중치의 값이 작아지기를 기대합니다.**
**즉, 적정한 가중치가 필요함을 의미합니다.**
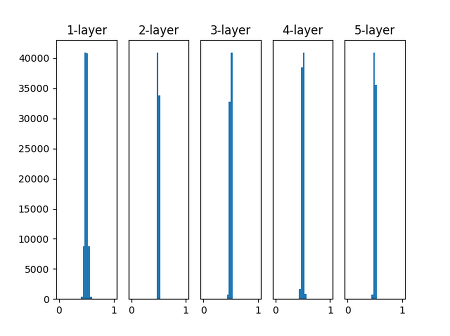
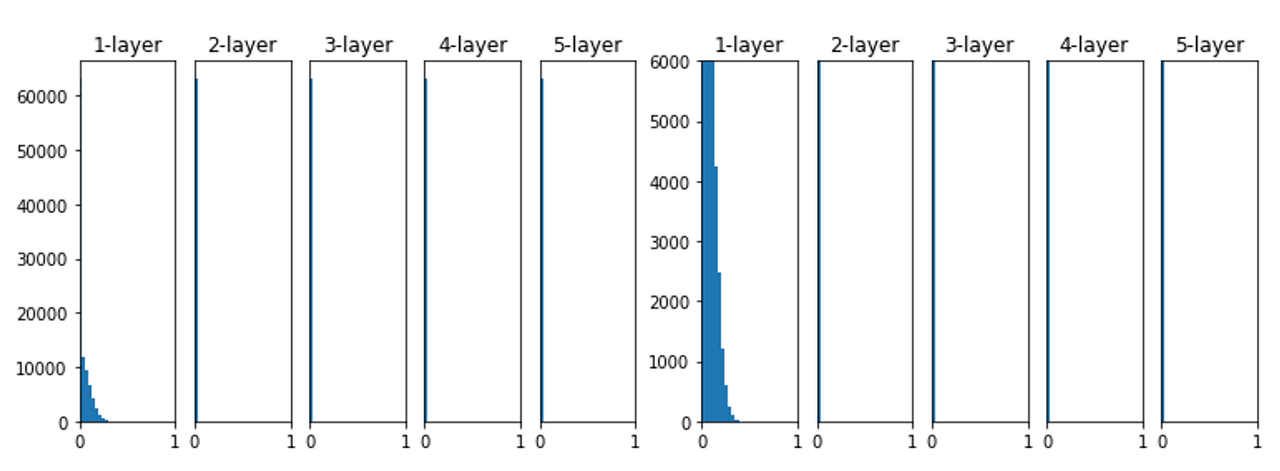
### 가중치를 큰 난수로 초기화 + sigmoid
그 다음으로 간단한 방법은 확률분포를 사용하는 방식입니다.
이 표준 정규분포를 따르도록 가중치를 랜덤하게 초기화를 하면 문제가 발생합니다.
대부분 -1 \~ 1사이의 값을 가지므로, 아주 큰 가중치를 가지게 됩니다.
가중치가 0과 1에 가까울 때, sigmoid 함수의 출력값이 0또는 1에 가까워 지게 됩니다.
sigmoid가 0에 1에 가까워지면 sigmoid의 미분값이 0에 가까워 지며 Gradient Vanishing
이 발생시키는 원인이 됩니다.
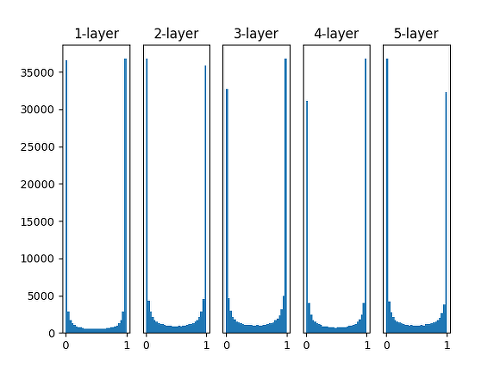
### 가중치를 아주 작은수로 초기화
가중치가 너무 작은 경우, 뉴런의 출력도 작아지게 됩니다.
입력 계층이 여러 layer를 지날수록 점점 0에 가깝게 변하며, 값이 0이 되는 순간
뉴런의 가중합이 0이 되어서 의미 있는 출력과 학습을 진행하지 못 하게 됩니다.
## 적정한 가중치란 어떤 값인가?
앞서 여러가지 case를 보면서 기울기 문제(vanishing, exploding)을 막기 위해
다음과 같은 결론을 내릴 수 있습니다.
1. **activation의 평균은 0이여야 합니다.**
2. **activation의 variance는 모든 layer에서 동일하게 유지되어야 합니다.**
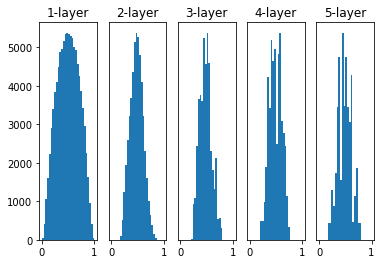
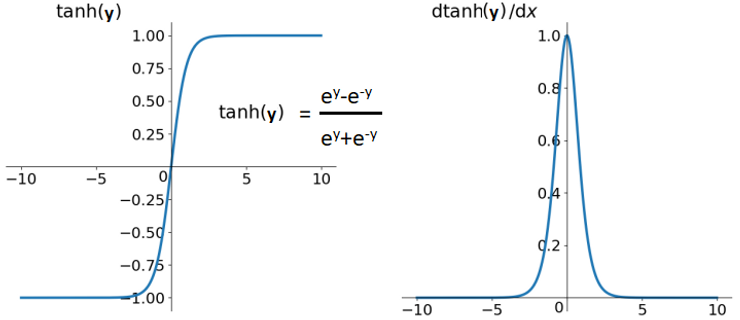
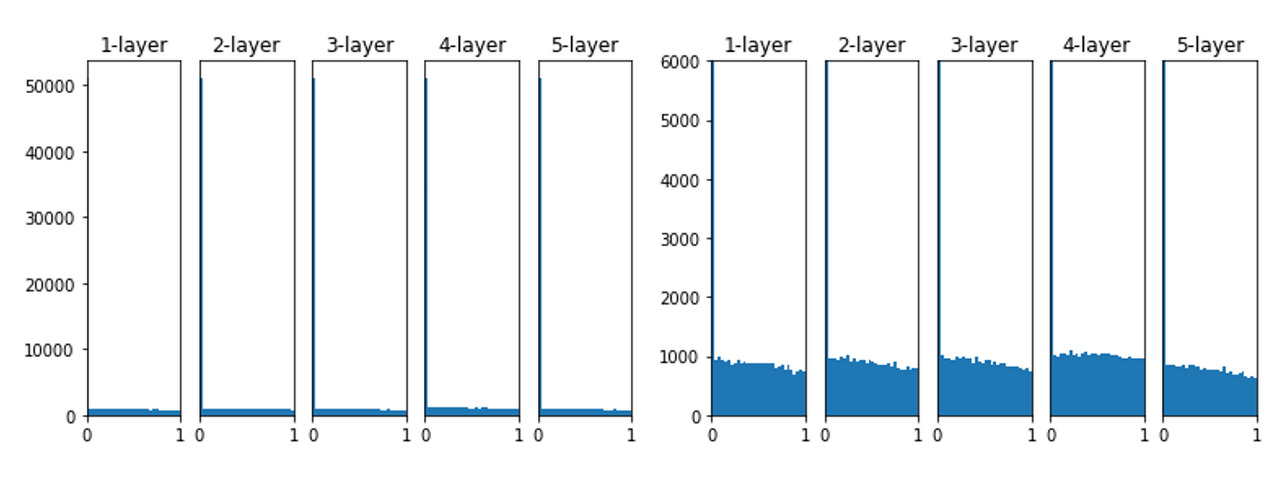
### Xavier 초기화
sigmoid 계열의 activation function을 사용할 때, 가중치를 초기화하는 방법입니다.
입력 데이터의 분산이 출력 데이터에서 유지되도록 가중치를 초기화 하는 방법입니다.
이전 layer의 neuron의 개수가 n이라면, $1 \over \sqrt n$인 분포를 사용하는 개념입니다.
너무 크지도 않고, 작지도 않은 weight를 사용하여 기울기문제를 막습니다.
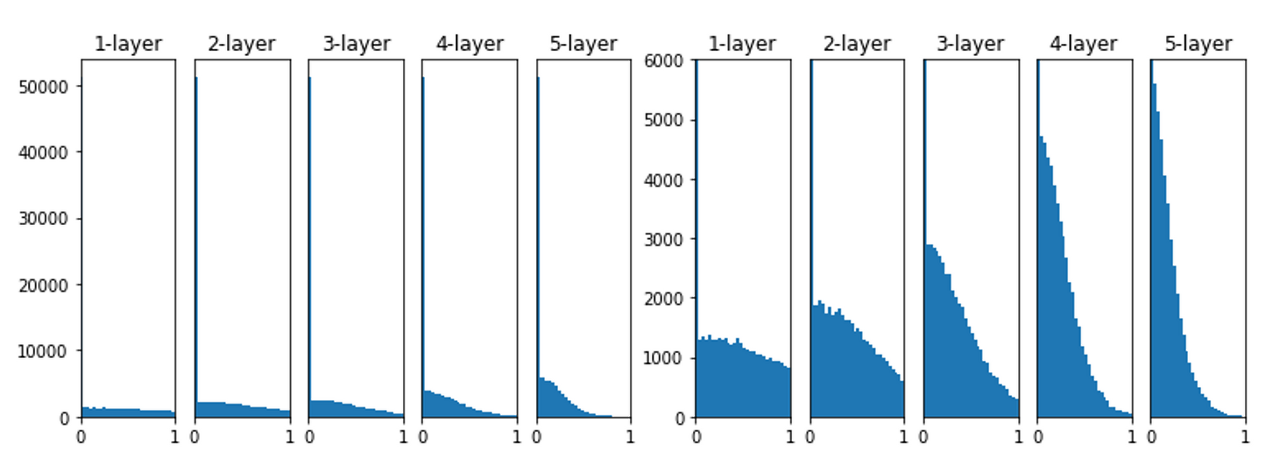
layer가 깊어지더라도, 앞에서 본 방식보다 더 넓게 분포됨을 알 수 있습니다.
이는 sigmoid 계열 함수를 사용하더라도 표현을 제한받지 않고 학습이 가능하다는 것입니다.
💡 Xavier는 tanh또는 sigmoid가 activation function일 때 가정한 초기화 입니다!
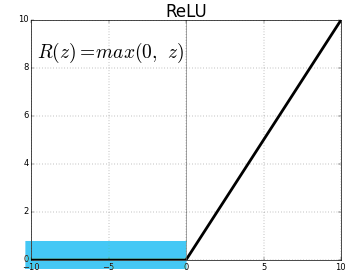
### He 초기화
activation function으로 ReLU일 때, Xavier 초기화를 사용하면 데이터의 크기가 점점 작아집니다.
sigmoid는 좌우대칭 이며, 중앙 부분이 선형이기 때문에 가능했습니다.
하지만 ReLU는 음수 구간에서 선형이 아니기 때문에, 분산이 절반이 됩니다.
표준편차 1로 학습했을 떄, layer가 깊어질 수록 치우치는 모습
표준편차 0.01로 했을 때, 학습이 되지 않는 모습
음의 구간에서 선형선이 없기 떄문에, 분산이 절반이 되었다.
**→ 분산을 두 배로 한다.**
## 정리
가중치 초기화는 학습 성능에 영향을 많이 끼칩니다.
좋은 시작점 역할을 하면서 gradient의 vanishing, exploding 문제를 완화 시킵니다.
Sigmoid 계열은 Xavier, ReLU는 He를 사용합니다.