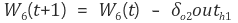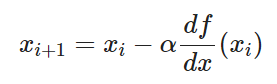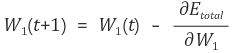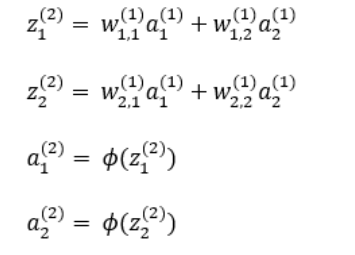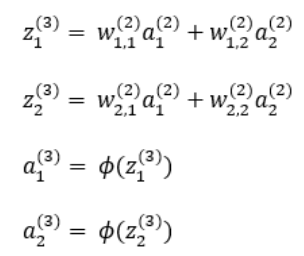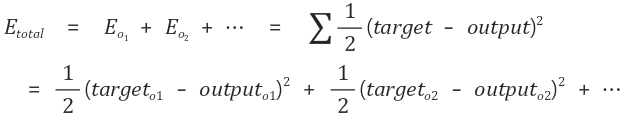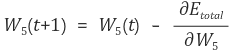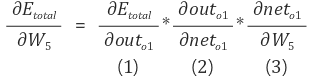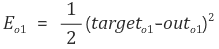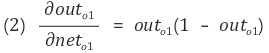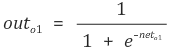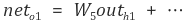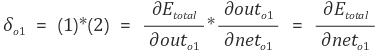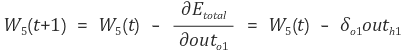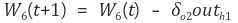# 7. 오류 역전파
1969년 단순 퍼셉트론은 XOR 문제도 풀 수 없다는 사실이 증명되었습니다. 다층 퍼셉트론으로 신경망을 구성하면 XOR 문제를 풀 수 있으나 이러한 MLP 을 학습시킬 수 있는 방법은 꽤오랜 시간 발견되지 않았고 딥러닝은 큰 침체기에 빠지게 됩니다.
이러한 MLP 를 학습시킬 수 있는 방법 즉, 딥러닝을 침체기로 부터 구해준 획기적인 방법이 바로 오류 역전파라는 개념입니다.
이 오류 역전파 알고리즘은 결국 경사하강법을 이용하기 때문에 오류 역전파를 살펴보기 전 경사하강법에 대해 잠시 리뷰하려고 합니다.
### 경사하강법 리뷰
### 1. 최적화 개념
딥러닝에서 최적화란 손실함수 값을 최소화 하는 파라미터를 구하는 과정입니다. 딥러닝에서는 학습 데이터를 입력하여 네트워크 구조를 거쳐 예측값을 얻게 됩니다. 이 예측값과 실제 정답값의 차이를 최소화 하는 네트워크 구조의 파라미터를 찾는 과정이 최적화 입니다.
이러한 최적화 기법에는 여러가지가 있는데 저는 그 중 경사 하강법에 대해 이야기 하려고 합니다.
### 2. 경사 하강법의 직관적인 의미
경사 하강법은 함수값이 낮아지는 방향으로 독립 변수값을 변형시켜 가면서 최종적으로는 최소 함수 값을 찾도록 하는 독립 변수 값을 찾는 방법입니다.
즉 어떠한 네트워크에서 함수값, 오차값이 낮아지는 방향으로 독립 변수, 파라미터의 값들을 변경시켜 제일 적은 오차를 갖도록 하는 변수들을 찾는 과정입니다.
경사하강법 앞이 보이지 않는 안개낀 산을 내려올 때 모든 방향으로 산을 더듬어가며 산의 높이가 가장 낮아지는 방향으로 한발짝씩 내딛는 과정과 유사합니다.
### 3. 경사 하강법의 목적과 사용 이유
경사 하강법은 앞서 말했든 함수의 최소값을 찾는 문제에서 활용됩니다.
맨 처음 세미나에서도 질문을 드렸듯이 함수의 최소, 최대를 찾으려면 단순히 “미분계수가 0인 지점을 찾으면 되지 않을까?” 라는 질문이 나올 수 있습니다.
미분계수가 0인 지점을 찾는 방식이 아닌 gradient descent 를 이용해 함수의 최소 값을 찾는 주된 이유는 다음과 같습니다.
* 우리가 주로 실제 분석에서 마주하게 되는 함수들은 닫힌 형태가 아니거나 함수의 형태가 복잡하여 미분계수와 그 근을 계산하기 어려움
* 실제 미분 계수를 계산하는 과정을 컴퓨터로 구현하는 것에 비해 gradient descent 는 컴퓨터로 비교적 쉽게 구현이 가능
* 데이터 양이 매우 큰 경우 gradient descent 와 같은 iterative 한 방법을 통해 이를 구하면 계산량 측면에서도 더 효율적으로 해를 구할 수 있음
### 4. 경사 하강법의 수식 유도
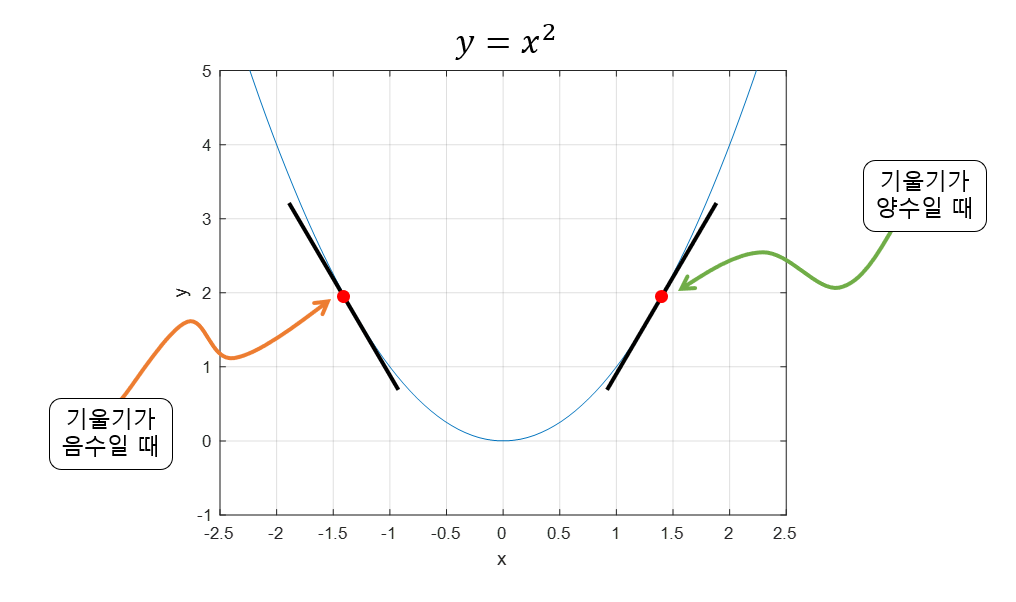
경사 하강법은 함수의 기울기 즉 gradient 를 통해 x 의 값을 어디로 옮겼을 때 함수가 최소값이 되는지 알아보는 방법입니다.
기울기가 양수라는 것은 x 값이 커질 수록 함수값이 커진다는 것이고
반대로 기울기가 음수라면 x 값이 커질수록 함수값이 작아진다는 것입니다.
또 기울기의 값이 크다는 것은 x 의 위치가 최소값/최댓값에 해당되는 x 좌표로부터 멀리 떨어져 있다는 것을 의미합니다.
**4-1. 기울기의 방향 성분을 이용**
위의 정의를 이용해 특정 포인트 x 에서 x 가 커질 수록 함수가 커지는 중이라면 음의 방향으로 x 를 옮겨야 할것이고 (기울기 부호가 양수)
반대로 특정 포인트 x 에서 x 가 커질수록 함수값이 작아지는 중이라면 양의 방향으로 x 를 옮겨야 할것입니다. (기울기 부호가 음수)
이를 수식으로 정의하면 다음과 같아집니다.
$$
Xi+1 = Xi - 이동거리 \* 기울기부호
$$
여기서 xi 와 xi+1 은 각각 i 번째 계산된 x 의 좌표와 i+1 번째 계산된 x 의 좌표를 의미하게 된다.
그렇다면 이동거리는 어떻게 생각해야할까?
**4-2. 기울기의 크기를 이용**
$$
Xi+1 = Xi - 이동거리 \* 기울기부호
$$
위의 식에서 이동거리는 어떻게 구할 수 있을까요?
만약 고정된 상수값으로 이동거리를 정한다고 가정해 보겠습니다.
만약 이동거리를 너무 크게 잡게 된다면 최적의 값을 놓치고 계속 그 지점 주위에서 맴돌 것입니다.
그렇다고 이동 거리를 너무 작게 잡는다면 빠르게 이동할 필요가 있을 때 즉 기울기의 절댓값이 클때는 너무 조금 이동하여 최적의 값을 찾는데 많은 시간이 걸릴 것입니다.
이 문제를 잘 해결하려면 미분계수 즉 기울기라는 것은 극솟값에가까워질 수록 그 값이 작아진다는 것을 알 수 있습니다.
따라서 이동 거리에 사용할 값을 gradient 크기와 비례하는 값을 사용하도록 한다면 현재 x 값이 극소값에서 멀 때는 많이 이동하고, 극소값에 가까워질 때는 조금씩 이동할 수 있게 될 것입니다.
즉, 이동 거리는 gradient 값을 직접 이용하되 이동 거리를 적절히 사용자가 조절할 수 있게 수식을 조정한다면
다음과 같은 공식으로 정의할 수 있을 것입니다.
### 오류 역전파
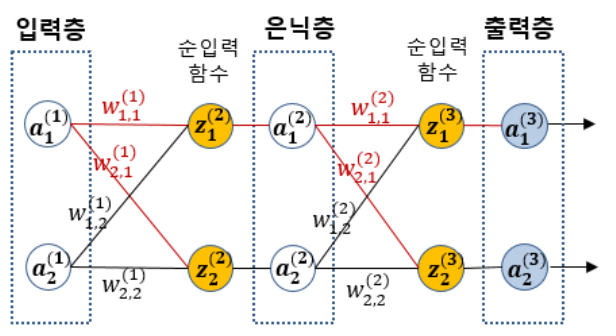
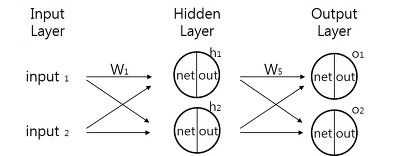
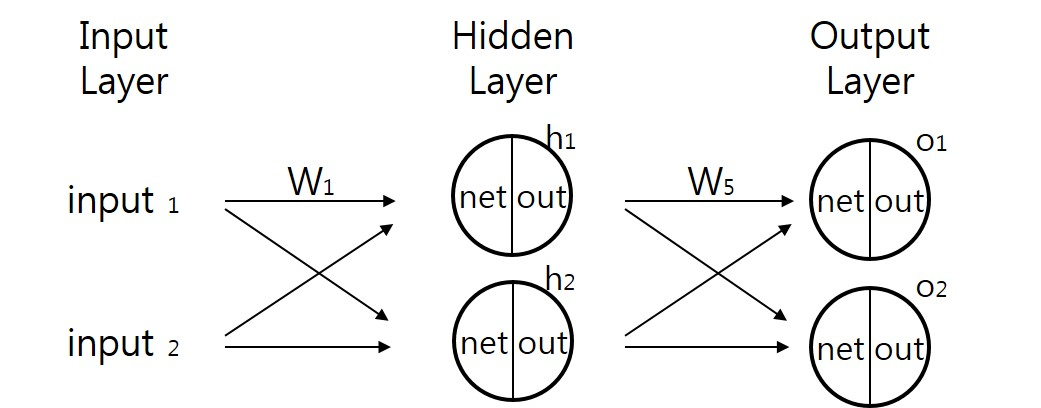
앞에서 말했듯 역전파 알고리즘도 결국 경사하강법을 사용합니다. 역전파가 무엇인지 알기 전에 MLP 에 순전파에 대해 정리해보도록 하겠습니다.
역전파의 개념 설명에 조금더 초점을 맞추기 위해 bias 값에 대한 것은 생략하도록 하겠습니다.
아래에 붙은 1 은 몇번째 노드인가에 관련한 것, 위에 붙은 (1) 은 몇번째 계층이냐에 관한 것입니다.
W2,1 은 2 번째 노드에서 1번째 노드로의 연결이라는 뜻이 됩니다.
즉 정리하면 다음과 같습니다.
1. 입력층에서 은닉층 사이의 값의 흐름
2. 은닉층에서 츨력층 사이의 값의 흐름
다음과 같이 입력층 a1(1), a2(1) 을 시작으로 a1(3), a2(3) 값이 출력되는 과정을 순전파라고 합니다.
다층 퍼셉트론에서도 마찬가지로 비용함수의 최소값을 찾아가는 방법으로 경사하강법을 사용합니다. 각 층에서 가중치를 업데이트 하기 위해서는 결국 각층에서의 비용함수의 미분값이 필요하기 때문입니다.
역전파를 이용한 가중치 업데이트 절차는 아래와 같이 요약됩니다.
1. 주어진 가중치 값을 이용해 출력층의 출력값을 계산함
2. 오차를 각 가중치로 미분한 값을 기존 가중치에서 빼준 (경사하강법을 사용)
3. 2번 단계를 모든 가중치들에 대해 적용
4. 1\~3 단계를 주어진 학습 횟수만큼, 주어진 허용 오차값에 도달할 때 까지 반복합니다
활성함수는 시그모이드이며
Etotal 은 각각 o1, o2 … 의 오차를 모두 더해준 것입니다.
최종 목적은 이 오차에 관한 함수 E 의 함수값을 0에 근사시키는 것입니다.
먼저 W5 를 기준으로 잡아보면
전체 오차 E 를 W5 로 편미분 한 값을 기존의 w5 에서 빼주면 w5 가 1회 갱신된 것입니다.
오차 E 를 w5 로 편미분 하면 chain rule 을 적용하여 다음과 같이 풀어낼 수 있습니다.
out o1 가 다른 오차에 영향을 미치지 않아 오차 E01 을 out 01 으로 미분한 값은 1/2 (target01 - out01)^2 이 된다.
out 과 net 의 편미분은 활성함수이므로 시그모이드 미분한 값이 나오게 된다.
net 은 각각의 가중치와 이전 곱의 합으로 이루어져 이전 node 의 out 값이 된다.
1번과 2번 값을 곱한 값을 다음과 같이 저장하고
w5 는 아래와 같이 갱신된다.
모든 가중치 값들에 대해 동일하게 성립하므로
따라서 각 가중치는 다음과 같아진다.
### 오류 역전파 알고리즘의 한계
역전파 알고리즘은 경사하강법이 가지고 있는 한계와 마찬가지로 항상 global minimum 을 찾는다고 보장할 수 없다.